BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers

Abstract
- BEVFormer learns unified BEV representations with spatiotemporal transformers to support multiple autonomous driving perception tasks.
-
BEVFormer exploits both spatial and temporal information by interacting with spatial and temporal space through predefined grid-shaped BEV queries.
- To aggregate spatial information, they design spatial cross-attention that each BEV query extracts the spatial features from the regions of interest across camera views.
- For temporal information, they propose temporal self-attention to recurrently fuse the history BEV information.
Introduction
Visual perception of the surrounding scene in autonomous driving is expected to predict the 3D bounding boxes or the semantic maps from 2D cues given by multiple cameras. Although previous map segmentation methods demonstrate BEV's effectiveness, BEV-based approaches have not shown significant advantage over other paradigm in 3D object detections.
Note
The underlying reason is that the 3D object detection task requires strong BEV features to support accurate 3D bounding box prediction, but generating BEV from the 2D planes is ill-posed.
Motivations
- A popular BEV framework that generates BEV features is based on depth information, but this paradigm is sensitive to the accuracy of depth values or the depth distributions. The detection performance of BEV-based methods is thus subject to compounding errors, and inaccurate BEV features can seriously hurt the final performance.
- The significant challenges are that autonomous driving is time-critical and objects in the scene change rapidly, and thus simply stacking BEV features of cross timestamps bring extra computational cost and interference information, which might not be ideal.
BEVFormer Overview
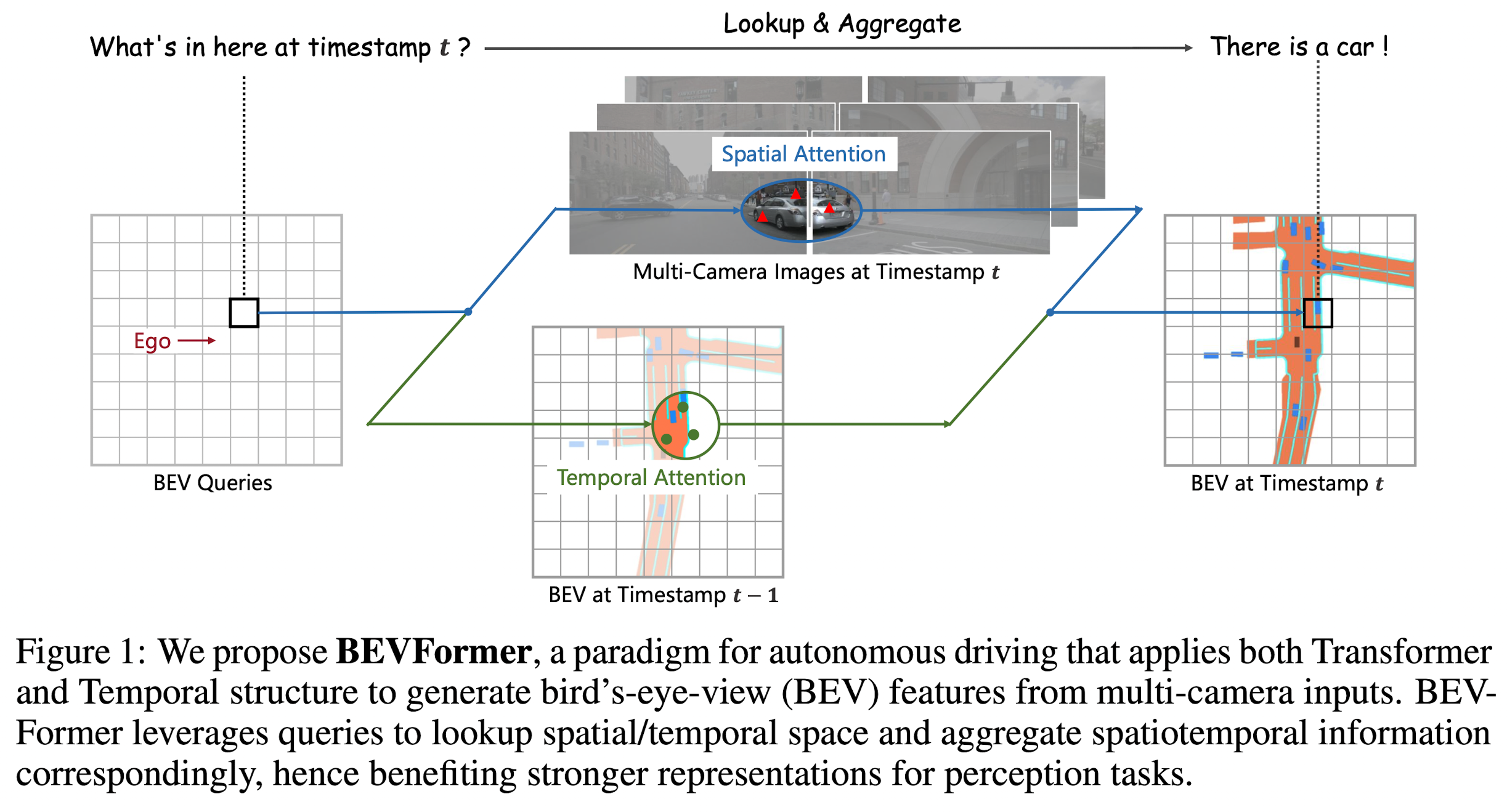
BEVFormer contains three key designs:
- grid-shaped BEV queries to fuse spatial and temporal features via attention mechanisms flexibly.
- spatial cross-attention module to aggregate the spatial features from multi-camera images.
- temporal self-attention module to extract temporal information from histogram BEV features, which benefits the velocity estimation of moving objects and the detection of heavily occluded objects, while brining negligible computational overhead.
With the unified features generated by BEVFormer, the model can collaborate with different task-specific heads such as Deformable DETR and mask decoder, for end-to-end 3D object detection and map segmentation.
Key Contributions
BEVFromer, a spatiotemporal transformer encoder that projects multi-camera and/or timestamp input to BEV representations.
BEVFormer
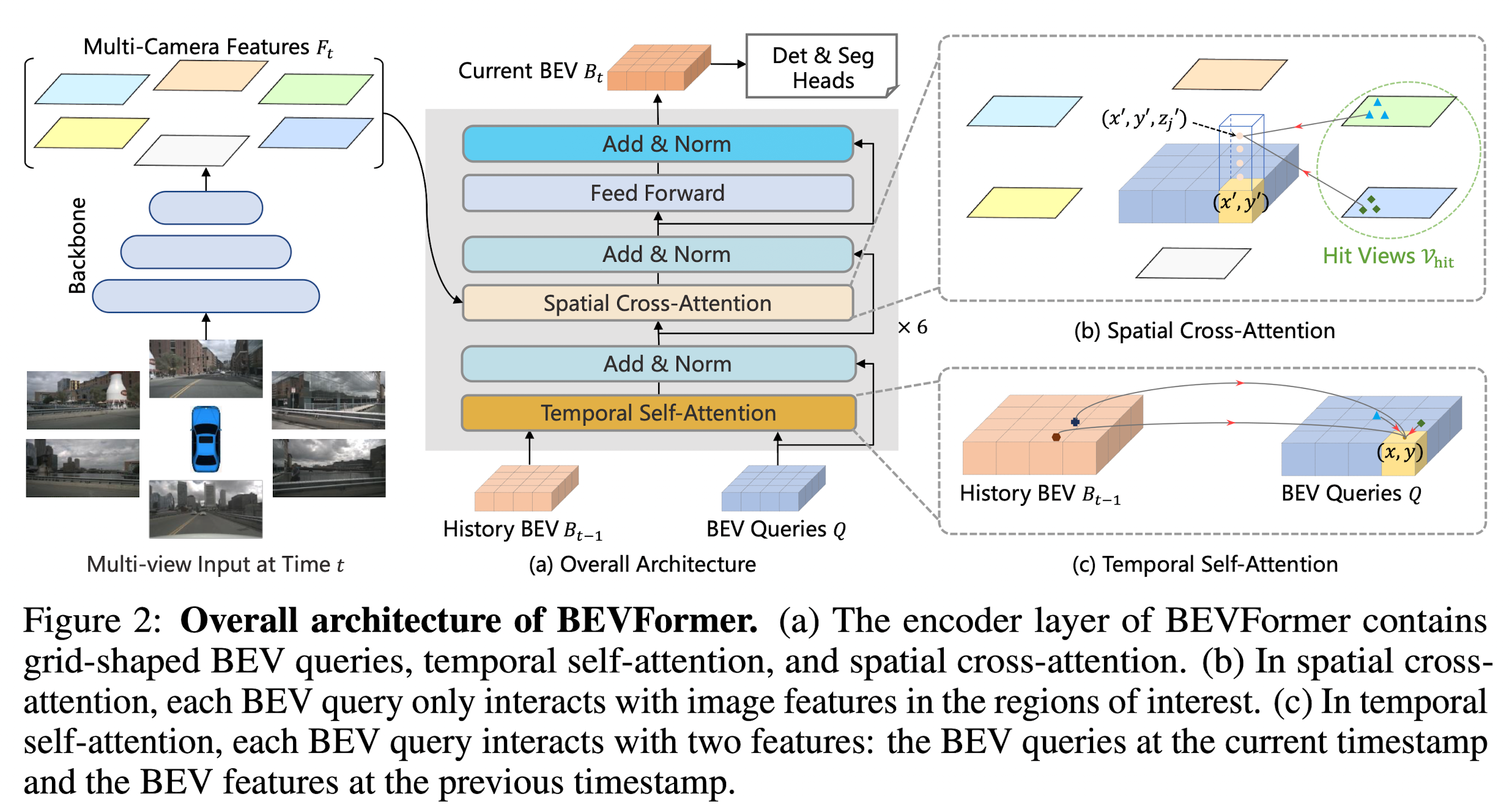
Overall Architecture
BEVFormer has 6 encoder layers, each of which follows the conventional structure of transformers, except for three tailored designs, namely BEV queries, spatial cross-attention, and temporal self-attention.