End-to-End Object Detection with Transformers

Abstract
- They present a new method that views object detection as a direct set prediction problem. This approach removes the need for many hand-designed components like a non-maximum suppression or anchor generation that explicitly encode prior knowledge about the task.
- The main ingredients of the new framework DETR (DEtection TRansformer) are a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture.
- DETR can be easily generalized to produce panoptic segmentation.
Introduction
The goal of object detection is to predict a set of bounding boxes and category labels for each object of interest. Modern detectors address this set prediction task in an indirect way, by defining surrogate regression and classification problems on a large set of proposals, anchors, or window centers.
Note
Their performance are significantly influenced by post-processing steps to collapse near-duplicate predictions, by the design of the anchor sets and by heuristics that assign target boxes to anchors.
DETR
This paper streamline the training pipeline by viewing object detection as a direct set prediction problem. They adopt an encoder-decoder architecture based on transformers.
Note
The self-attention mechanisms of transformers, which explicitly model all pair wise interactions between elements in a sequence, make these architectures particularly suitable for specific constraints of set prediction such as removing duplicate predictions.
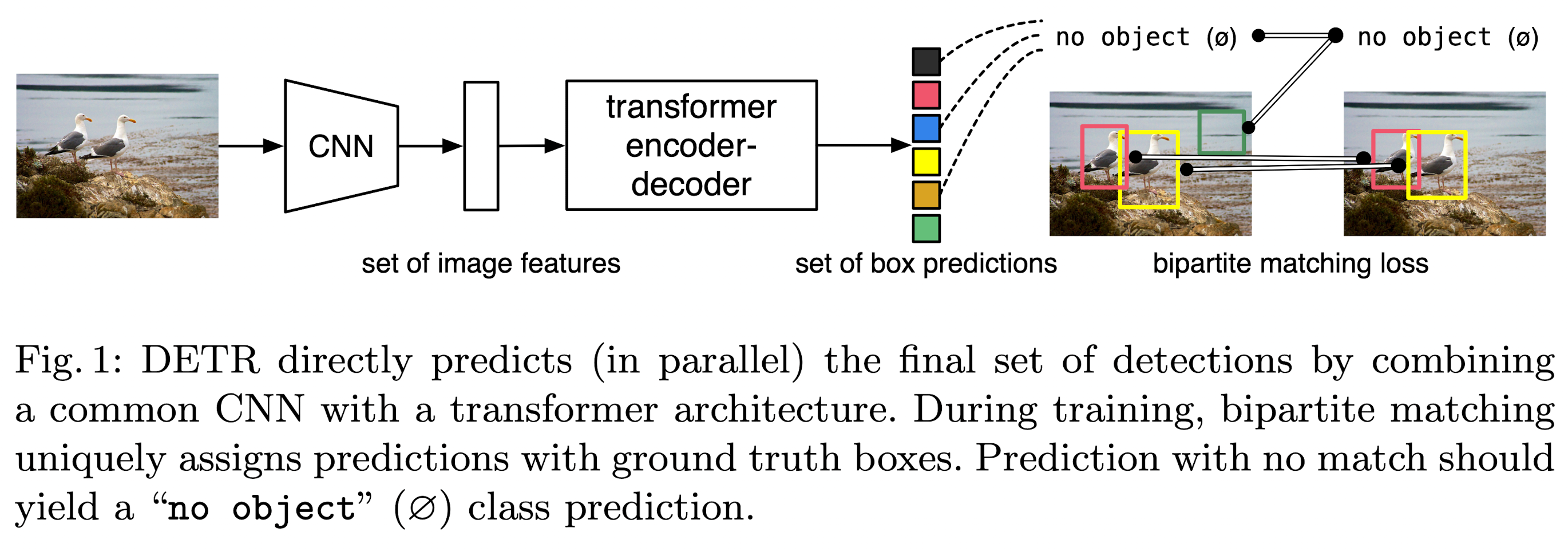
- The DETR predicts all objects at once, and is trained end-to-end with a set loss function which performs bipartite matching between predicted and ground-truth objects.
- Compared to most previous work on direct set prediction, the main features of DETR are the conjunction of the bipartite matching loss and transformers with (non-autoregressive) parallel decoding.
Training settings for DETR differ from standard object detectors in multiple ways. The new model requires extra-long training schedule and benefits from auxiliary decoding losses in the transformer.
Related Work
Set Prediction
In all cases, the loss function should be invariant by a permutation of the predictions. The usual solution is to design a loss based on the Hungarian algorithm, to find a bipartite matching between ground-truth and prediction. This enforces permutation-invariance, and guarantees that each target element has a unique match.
Transformers and Parallel Decoding
Note
One of the main advantages of attention-based models is their global computations and perfect memory, which makes them more suitable than RNNs on long sequences.
Transformers were first used in auto-regressive models, following early sequence-to-sequence models, generating output tokens one by one. However, the prohibitive inference cost (proportional to output length, and hard to batch) lead to the development of parallel sequence generation.
Object Detection
Most modern object detection methods make predictions make predictions relative to some initial guesses. Recent work demonstrate that the final performance of these systems heavily depends on the exact way these initial guesses are set.
The DETR Model
Two ingredients are essential for direct set predictions in detection:
- a set prediction loss that forces unique matching between predicted and ground truth boxes.
- an architecture that predicts (in a single pass) a set of objects and models their relation.
Object Detection Set Prediction Loss
DETR infers a fixed-size set of \(N\) predictions, in a single pass through the decoder, where \(N\) is set to be significantly larger than the typical number of objects in an image.
Note
One of the main difficulties of training is to score predicted objects (class, position, size) with respect to the ground truth.
The proposed loss produces an optimal bipartite matching between predicted and ground truth objects, and then optimize object-specific (bounding box) losses. The matching cost takes into account both the class prediction and the similarity of predicted and ground truth boxes.
- In the bipartite graph matching, they use probabilities for matching classes. But they use log-probabilities in the Hungarian loss.
- The most commonly-used l1 loss will have different scales for small and large boxes even if relative errors are similar. To mitigate this issue they use a linear combination of the l1 loss and the generalized IoU loss.
DETR Architecture
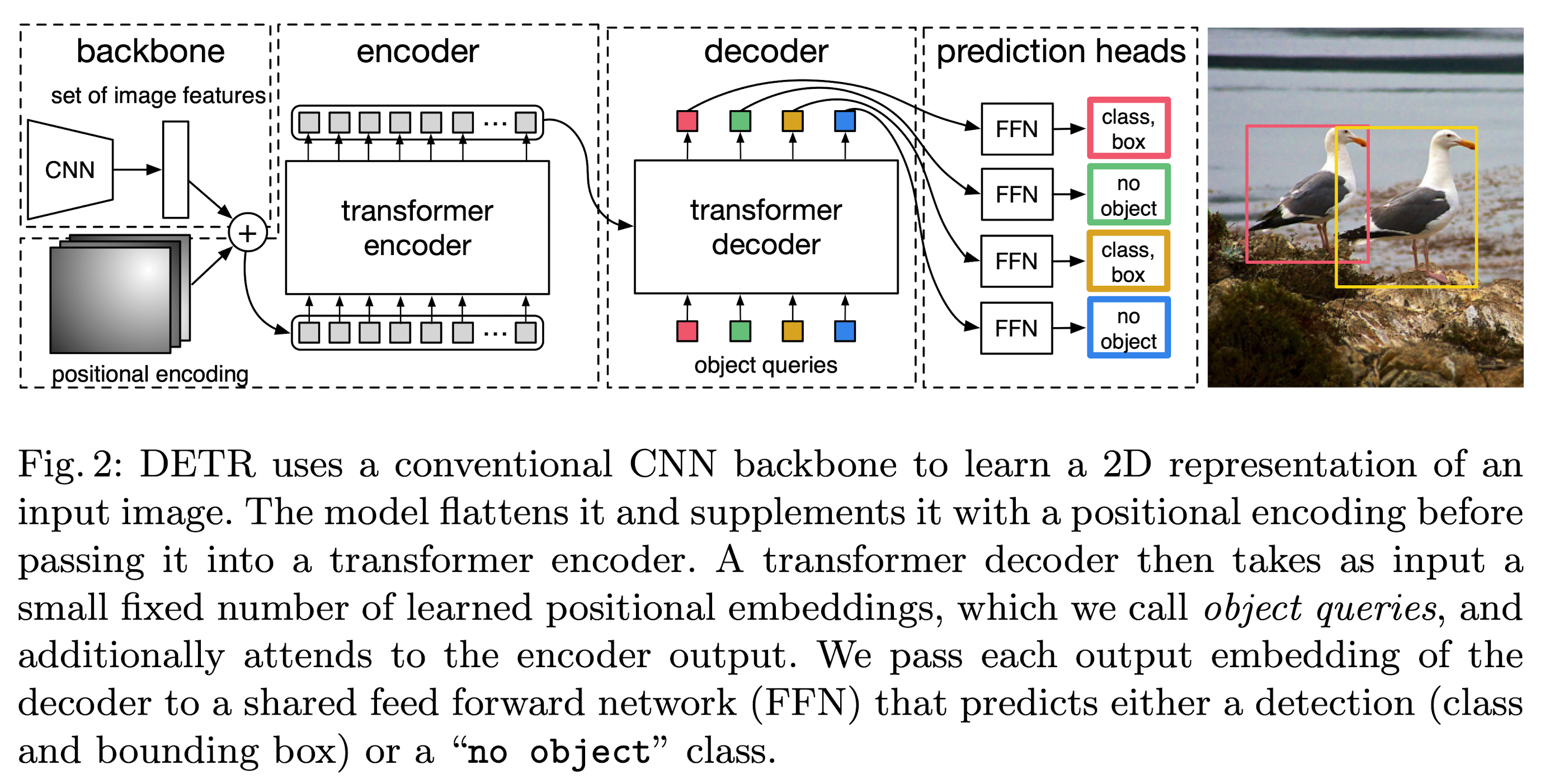
Transformer Encoder
The encoder expects a sequence as input, hence they collapse the spatial dimensions of \(z_0\) into one dimension, resulting a \(d \times HW\) feature map.
Transformer Decoder
The difference with the original transformer is that the new model decodes the \(N\) objects in parallel at each decoder layer, while the original transformer uses an auto-regressive model that predicts the output sequence one element at a time.
Since the decoder is also permutation-invariant, the \(N\) input embeddings must be different to produce different results. These input embeddings are learnt positional encodings that they refer to as object queries, and similarly to the encoder, they add them to the input of each attention layer.
Note
- The \(N\) object queries are transformed into an output embedding by the decoder in parallel.
- They are then independently decoded into box coordinates and class labels by a feed forward network, resulting \(N\) final predictions.
Prediction Feed-forward Networks (FFNs)
The final prediction is computed by a 3-layer perceptron with ReLU activation function and hidden dimension \(d\), and a linear projection layer.
Auxiliary Decoding Losses
They found it is helpful to use auxiliary losses in decoder during training, especially to help the model output the correct number of objects of each class.
- They add prediction FNNs and Hungarian loss after each decoder layer.
- All prediction FFNs share their parameters.
- They use an additional shared layer-norm to normalize the input to the prediction FFNs from different decoder layers.