FCOS: Fully Convolutional One-Stage Object Detection

Abstract
They propose a fully convolutional one-stage object detector (FCOS) to solve object detection in a per-pixel prediction fashion, analogue to semantic segmentation. The proposed detector FCOS is anchor box free, as well as proposal free.
- avoid the complicated computation related to anchor boxes such as calculating overlapping during training.
- avoid all hyper-parameters related to anchor boxes, which are often very sensitive to the final detection performance.
FCOS: a much simpler and flexible detection framework achieving improved detection accuracy.
Introduction
Anchor Based Detection
All current mainstream detectors such as Faster R-CNN, SSD and YOLOv2, v3 rely on a set of pre-defined anchor boxes and it has long been believed that the use of anchor boxes is the key to detectors' success. Despite their great success, it is important to note that anchor-based detectors suffer some drawbacks:
- Detection performance is sensitive to the sizes, aspect ratios and number of anchor boxes. These hyper-parameters need to be carefully tuned in anchor-based detectors.
- Even with careful design, because the scales and aspect ratios of anchor boxes are kept fixed, detectors encounter difficulties to deal with object candidates with large shape variations, particularly for small objects. The pre-defined anchor boxes also hamper the generalization ability of detectors, as they need to be re-designed on new detection tasks with different object sizes or aspect ratios.
- In order to achieve a high recall rate, an anchor-based detector is required to densely place anchor boxes on the input image. Most of these anchor boxes are labelled as negative samples during training. The excessive number of negative samples aggravates the imbalance between positive and negative samples in training.
- Anchor boxes also involve complicated computation such as calculating the IoU scores with ground-truth bounding boxes.
Fully Convolutional Networks (FCNs)
In the literature, some works attempted to leverage the FCNs-based framework for object detection such as DenseBox. However, to handle the bounding boxes with different sizes, DenseBox crops and resizes training images to a fixed scale. Thus DenseBox has to perform detection on image pyramids, which is against FCN's philosophy of computing all convolutions once. In addition, it is believed that these methods do not work well when applied to generic object detection with highly overlapped bounding boxes.

Warning
The highly overlapped bounding boxes result in an intractable ambiguity: it is not clear w.r.t. which bounding box to regress for the pixels in the overlapped regions.
They took a closer look at the issue and show that with FPN this ambiguity can be largely eliminated.
- their method can obtain comparable detection accuracy with those traditional anchor based detectors.
- their method may produce a number of low-quality predicted bounding boxes at the locations that are far from the center of an target object. In order to suppress these low-quality detections, they introduce a novel "center-ness" branch (only one layer) to predict the deviation of a pixel to the center of its corresponding bounding boxes.
Related Work
Anchor-based Detectors.
Hint
Anchor-based detectors inherit the ideas from traditional sliding-window and proposal based detectors such as Fast R-CNN.
In anchor-based detectors, the anchor boxes can be viewed as pre-defined sliding windows or proposals, which are classified as positive or negative patches, with an extra offsets regression to refine the prediction of bounding box locations. Therefore, the anchor boxes in these detectors may be viewed as training samples.
The design of anchor boxes are popularized by Faster R-CNN in its RPNs, SSD and YOLOv2, and has become the convention in a modern detector.
Anchor-free Detectors
YOLOv1
The most popular anchor-free detector might be YOLOv2. Instead of using anchor boxes, YOLOv1 predicts bounding boxes at points near the center of objects.
Note
Only the points near the center are used since they are considered to be able to produce higher quality detection. However, since only points near the center are used to predict bounding boxes, YOLOv1 suffers from low recall.
Compared to YOLOv1, FCOS takes advantages of all points in a ground truth bounding box to predict the bounding boxes and the low-quality detected bounding boxes are suppressed by the proposed "center-ness" branch.
CornerNet
CornerNet is a recently proposed one-stage anchor-free detector, which detects a pair of corners of a bounding box and groups them to form the final detected bounding box. CornerNet requires much more complicated post processing to group the pairs of corners belonging to the same instance. An extra distance metric is learned for the purpose of grouping.
Proposed Approach
Fully Convolutional One-Stage Object Detector
Different from anchor-based detectors, which consider the location on the input image as the center of (multiple) anchor boxes and regress the target bounding box with these anchor boxes as references, they directly regress the target bounding box at the location. In other words, their detector directly views locations as training samples instead of anchor boxes in anchor-based detectors, which is the same as FCNs for semantic segmentation.
Note
Specifically, location \((x, y)\) is considered as a positive sample if it falls into any ground-truth box and the class labels \(c^*\) of the location is the class label of the ground truth box. Otherwise it is a negative sample and \(c^* = 0\) (background class).
Besides the label for classification, they also have a 4D real vector being the regression targets for the location.
If a location falls into multiple bounding boxes, it is considered as an ambiguous sample. They simply choose the bounding box with minimal area as its regression target.
Hint
It is worth noting that FCOS can leverage as many foreground samples as possible to train the regressor. It is different from anchor-based detectors, which only consider the anchor boxes with a highly enough IoU with ground-truth boxes as positive samples.
Network Outputs
It is worth noting that FCOS has \(9 \times\) fewer network output variables than the popular anchor based detectors with 9 anchor boxes per location.
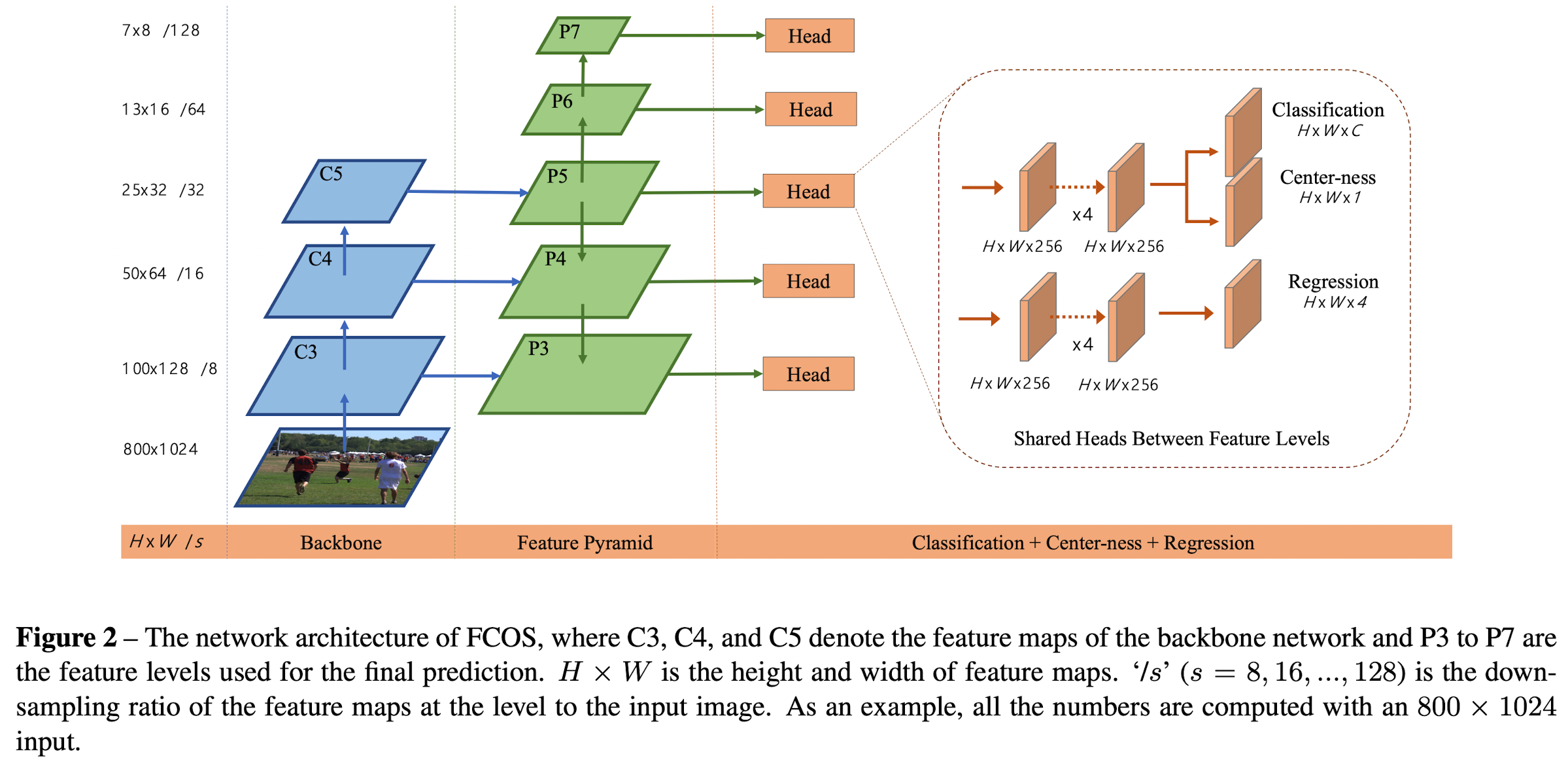
Multi-level Prediction with FPN for FCOS
Two possible issues of the proposed FCOS can be resolved with multi-level prediction with FPN.
- The large stride (e.g., \(16 \times\)) of the final feature maps in a CNN can result in a relatively low best possible recall (BPR).
- Overlaps in ground-truth boxes can cause intractable ambiguity.
Unlike anchor-based detectors, which assign anchor boxes with different sizes to different feature levels, they directly limit the range of bounding box regression for each level.
Since objects with different sizes are assigned to different feature levels and most overlapping happens between objects with considerably different sizes. If a location, even with multi-level prediction used, is still assigned to more than one ground-truth boxes, they simply choose the ground-truth box with minimal area as its target.
Hint
They share the heads between different feature levels, not only making the detector parameter-efficient but also improving the detection performance.
Instead of using the standard \(exp(x)\), they make use of \(exp(s_ix)\) with a trainable scalar \(s_i\) to automatically adjust the base of the exponential function for feature level \(P_i\), which slightly improves the detection performance.
Center-ness for FCOS
After using multi-level prediction in FCOS, there is still a performance gap between FCOS and anchor-based detectors. They observed that it is due to a lot of low-quality predicted bounding boxes produced by locations far away from the center of an object.
They add a single-layer branch, in parallel with the classification branch to predict the "center-ness" of a location. The center-ness depicts the normalized distance from the location to the center of the object that the location is responsible for.