Monocular BEV Perception
Approaches
- IPM
- Lift-splat
- MLP
- Transformers
View Transformation with Transformers
Transformers are more suitable to perform the job of view transformation due to the global attention mechanism.
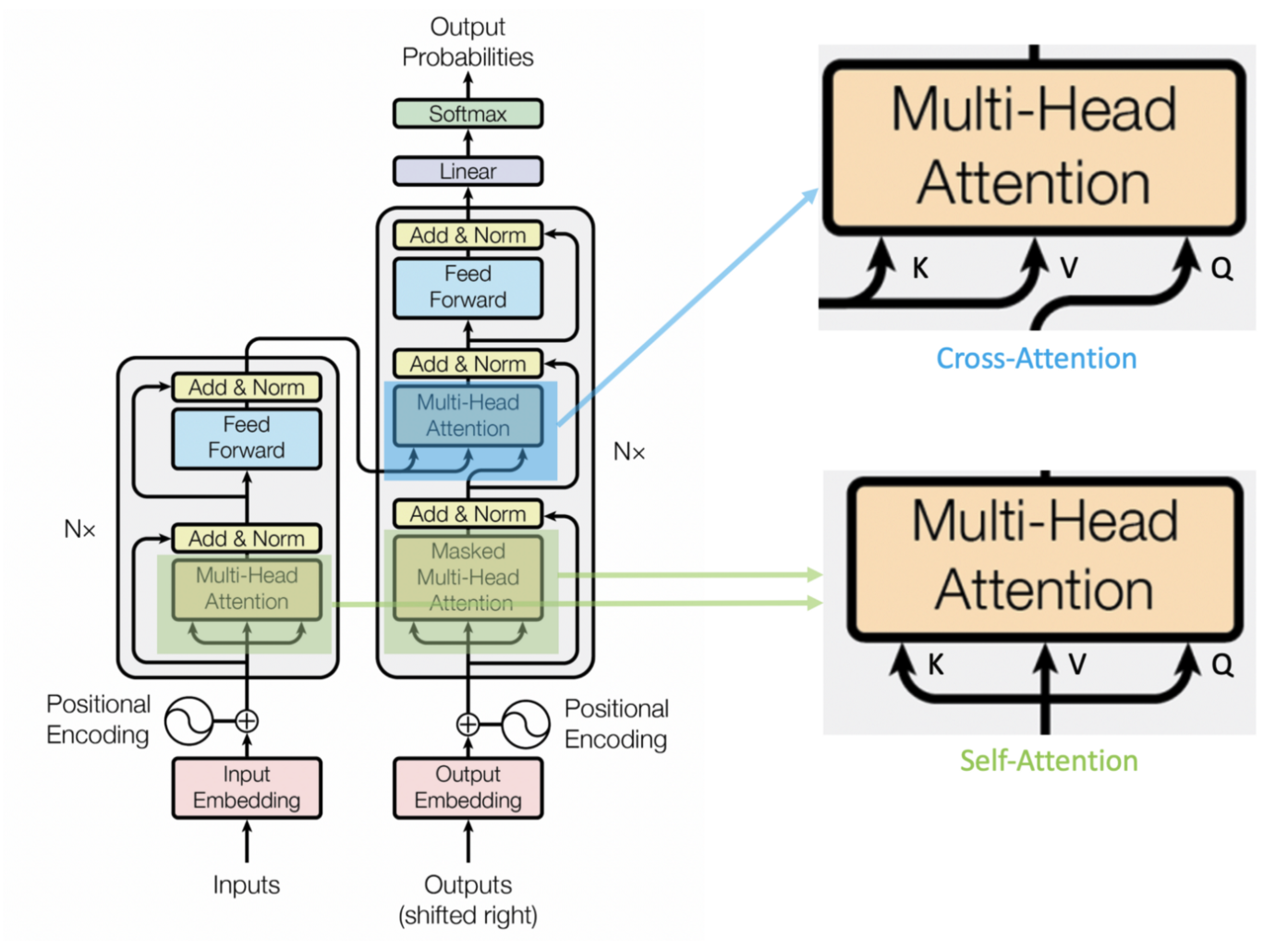
There are two types of attention mechanisms in Transformers, self-attention in the Encoder and cross-attention in the decoder. The main difference between them is the query \(Q\). - In self-attention, the \(Q\), \(K\), \(V\) inputs are the same. - In cross-attention, \(Q\) is in a different domain from that for \(K\) and \(V\).
Cross-attention Is All You Need
Many of the recent advances in Transformers in CV actually only leverages the self-attention mechanism. They act as an enhancement to the backbone feature extractor.
Warning
Considering the difficulty in the deployment of the general Transformer architecture in resource-limited embedded systems typical on mass production vehicles, the incremental benefit of self-attention over the well-supported CNN can be hard to justify.
Until we see some groundbreaking edge of self-attention over CNN, it would be wise choice to focus on CNN for industry applications.
Cross-attention
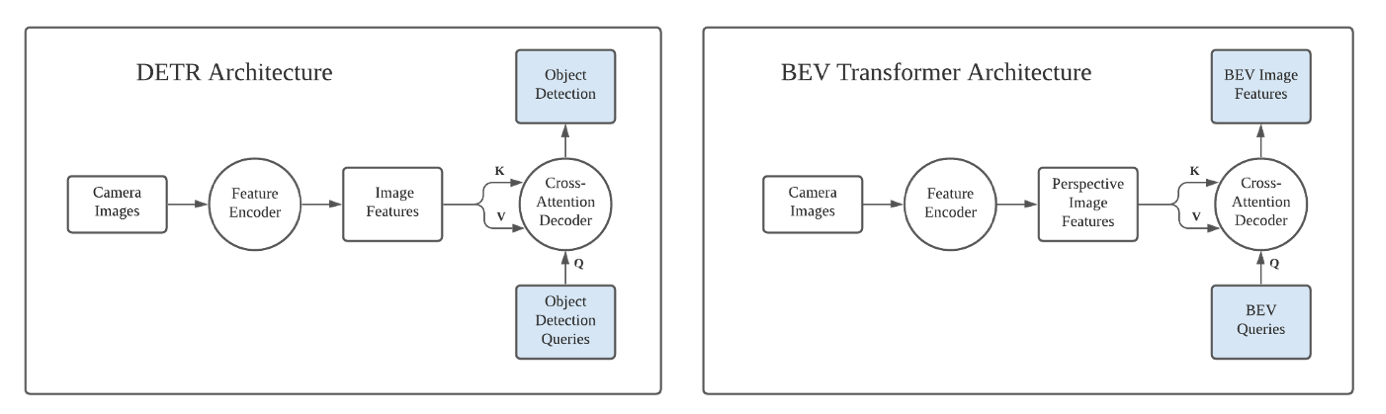
One pioneering study of applying cross-attention to computer vision is DETR. One of the most innovative parts of DETR is the cross-attention decoder based on a fixed number of slots called object queries. The content of the queries are also learned and do not have to be specified before training, except the number of the queries.
Hint
These queries can be viewed as a blank, preallocated template to hold object detection results, and the cross attention decoder does the work of filling in the blanks.
This prompts the idea of using the cross-attention decoder for view transformation. - The input view is fed into a feature encoder (either self-attention based or CNN-based), and the encoded features serve as \(K\) and \(V\). - The query \(Q\) in target view format can be learned and only need to be rasterized as a template. The values of \(Q\) can be learned jointly with the rest of the network.