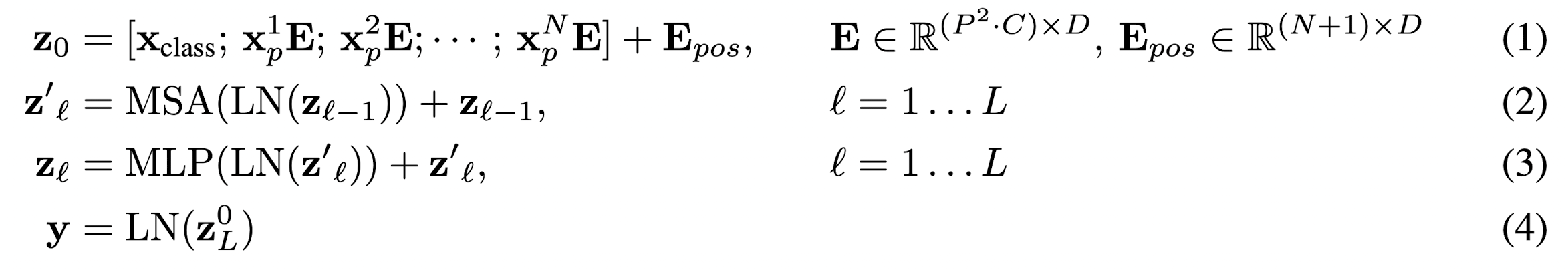Vision Transformer
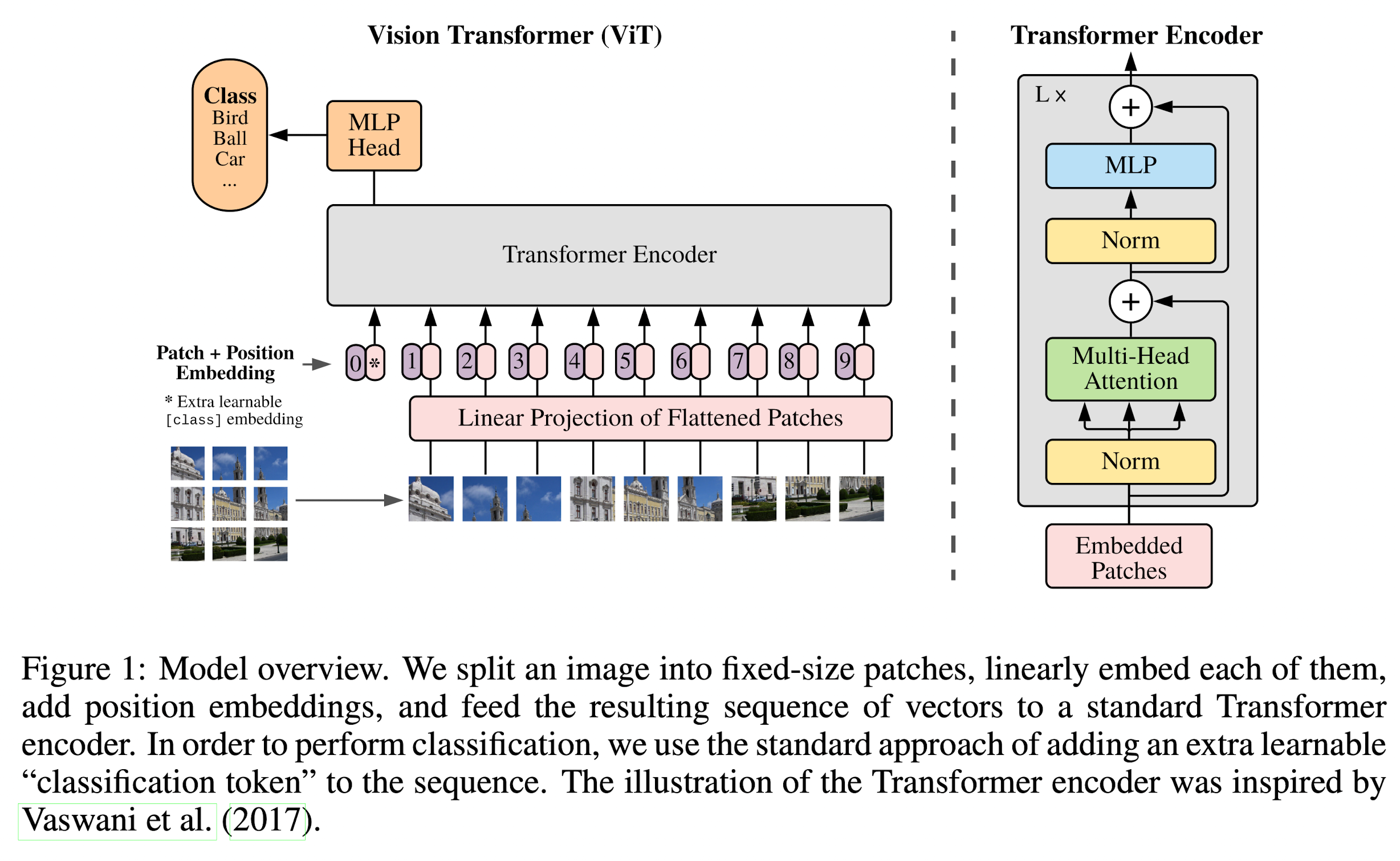
The standard Transformer receives as input a 1D sequence of token embeddings. To handle 2D images, they reshape the image \(x \in \mathbb{R}^{H \times W \times C}\) into a sequence of flattened 2D patches \(N \times \textbf{x}_p \in \mathbb{R}^{P^2 \cdot C}\), where \((H, W)\) is the resolution of the original image, \(C\) is the number of channels, \((P, P)\) is the resolution of each image patch, and \(N = HW / P^2\) is the resulting number of patches, which also serves as the effective input sequence length for the Transformer.
Note
The Transformer uses constant latent vector size \(D\) through all of its layers, so they flatten the patches and map to \(D\) dimensions with a trainable linear projection.
Classification Head
Similar to BERT's [class] token, they prepend a learnable embedding to the sequence of embedded patches (\(\textbf{z}^0_0 = \textbf{x}_{class}\)), whose state at the output of the Transformer encoder (\(\textbf{z}_L^0\)) serves as the image representation \(\textbf{y}\). Both during pre-training and fine-tuning, a classification head is attached to \(\textbf{z}_L^0\).
Note
The classification head is implemented by a MLP with one hidden layer at pre-training time and by a single linear layer at fine-tuning time.
Position Embedding
Position embeddings are added to the patch embeddings to retain positional information. They use standard learnable 1D position embeddings.