Multimodal Transformer for Automatic 3D Annotation and Object Detection

Abstract
- To automate the annotation and facilitate the production of various customized datasets, they propose an end-to-end multimodal transformer (MTrans) autolabeler, which leverages both LiDAR scans and images to generate precise 3D box annotations from weak 2D bounding boxes.
- To alleviate the pervasive sparsity problem that hinders existing autolabelers, MTrans densifies the sparse point clouds by generating new 3D points based on 2D image information.
- With a multi-task design, MTrans segments the foreground/background, densifies LiDAR point clouds, and regresses 3D boxes simultaneously.
Introduction
Compared with 3D annotations, 2D bounding boxes are much easier to obtain. Hence, they investigate the generation of 3D annotations from weak 2D boxes. Even though the problem domain is narrowed down by the weak 2D annotations, it is still challenging to generate a 3D box if the points are too sparse, due to the ambiguity in orientation and scale.
Note
The sparsity problem remains a fundamental challenge for automatic annotations.
Besides the sparsity issue, point clouds lack color information. Fortunately, images provide dense fine-grid RGB information, which is an effective complement to the sparse point clouds. Motivated by this, they investigate point cloud enrichment with image information.
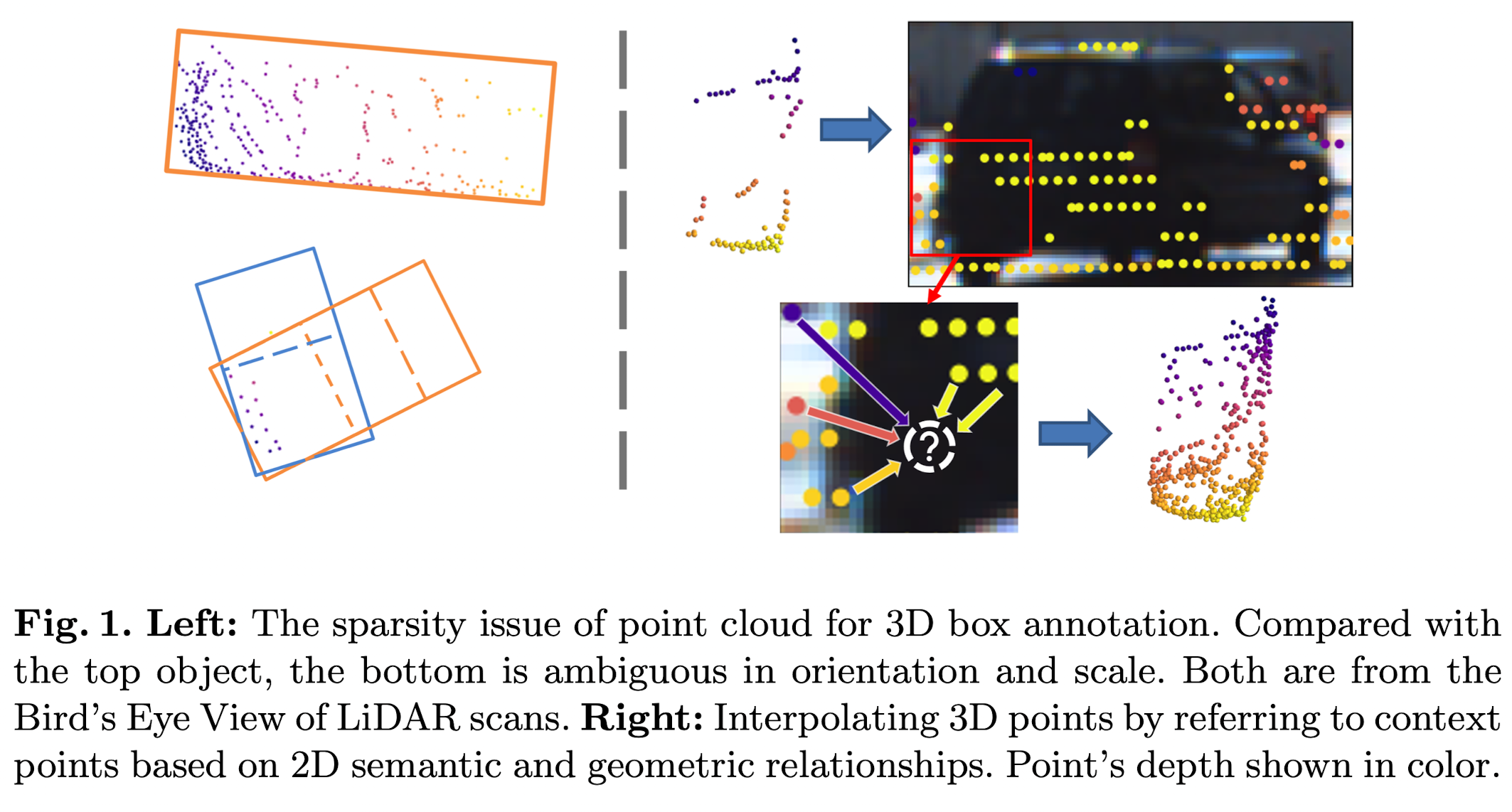
3D LiDAR points can be projected onto the image, and therefore an image pixel's 3D coordinates can be estimated by referring to the context LiDAR points, based on their 2D spatial and semantic relationships. This way, new 3D points can be generated from 2D pixels, and hence densify the sparse point cloud.
- In order to leverage the dense image information to enrich sparse point clouds, they present the multimodal self-attention module, which efficiently extracts multimodal 2D and 3D features, modeling points' geometric and semantic relationships.
- To train MTrans, they introduce a multi-task design, so that it learns to generate new 3D points to reduce the sparsity of point clouds while predicting 3D boxes.
- Moreover, to exploit unlabelled data for the point generation task, a mask-and-predict self-supervision strategy can be carried out.
MTrans for Automatic Annotation
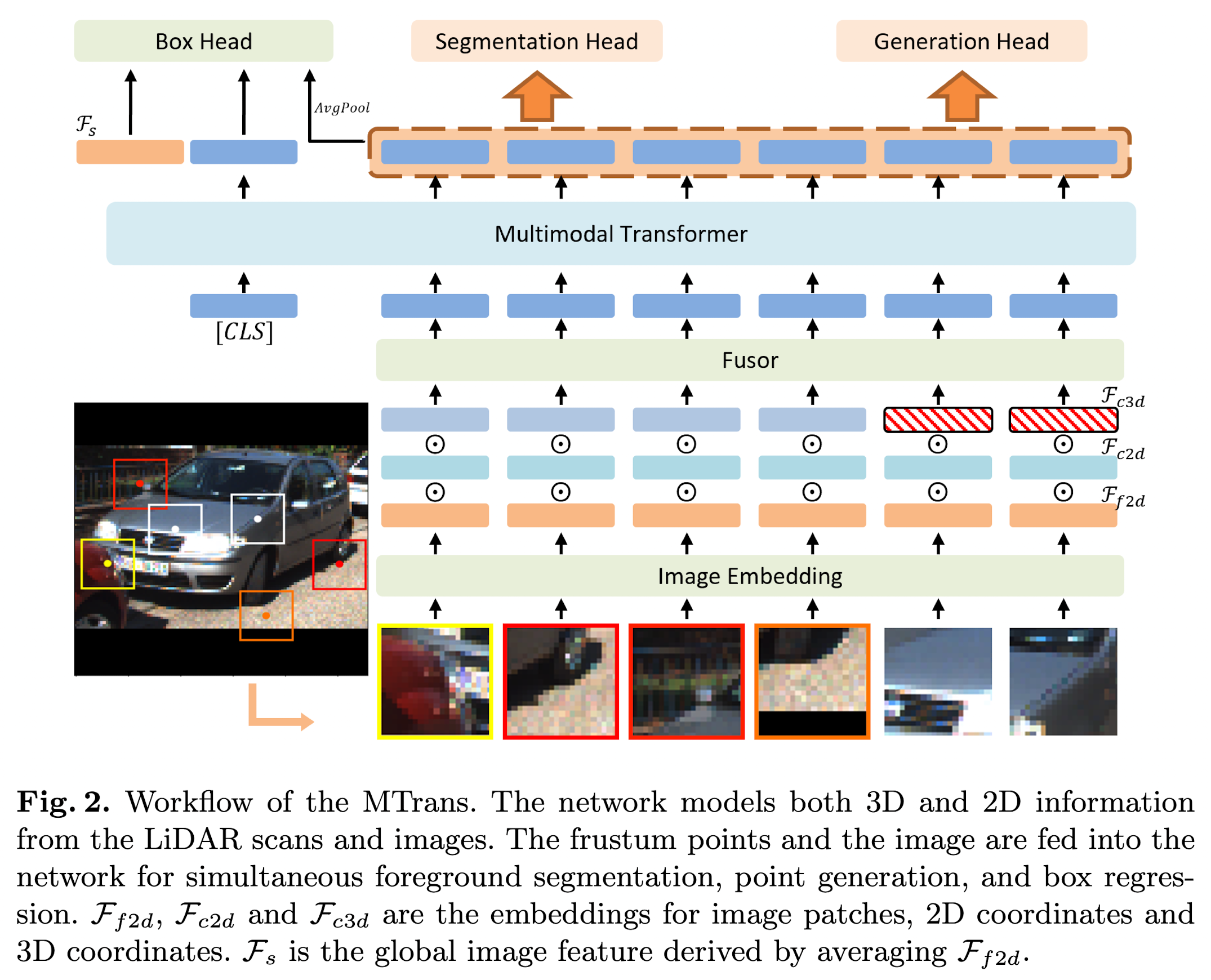
Data Preparation
MTrans generates one 3D bounding box for each object in a weak 2D box.