An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale

Abstract
- In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place.
- They show that the reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks.
- Vision Transformer (ViT) can attain excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
Introduction
Inspired by the Transformer scaling successes in NLP, they experiment with applying a standard Transformer directly to images, with the fewest pssible modifications.
Note
They split an image into patches and provide the sequence of linear embeddings of these patches as an input to a Transformer. Image patches are treated the same way as tokens (words) in an NLP application.
Related Work
Naive application of self-attention to images would require that each pixel attends to every other pixel. With quadratic cost in the number of pixels, this does not scale to realistic input sizes. Several approximations have been tried:
- Apply the self-attention only in local neighborhoods for each query pixel instead of globally. Such local multi-head dot-product self attention blocks can completely replace convolutions.
- Sparse Transformers employ scalable approximations to global self attention in order to be applicable to images.
- Apply self attention in blocks of varying sizes.
- ...
Warning
Many of these specialized attention architectures demonstrate promising results on computer vision tasks, but require complex engineering to be implemented efficiently on hardware accelerators.
A very similar work is On the Relationship between Self-Attention and Convolutional Layers (ICLR 2020). The main differences are
- this work goes further to demonstrate that large scale pre-training makes vanilla transformers competitive with (or even better than) state-of-the-art CNNs.
- this work uses a larger patch size, which makes the model applicable to medium-resolution images as well.
Method
ViT follow the original Transformer as closely as possible. An advantage of this intentionally simple setup is that scalable NLP Transformer architectures - and their efficient implementations - can be used almost out of the box.
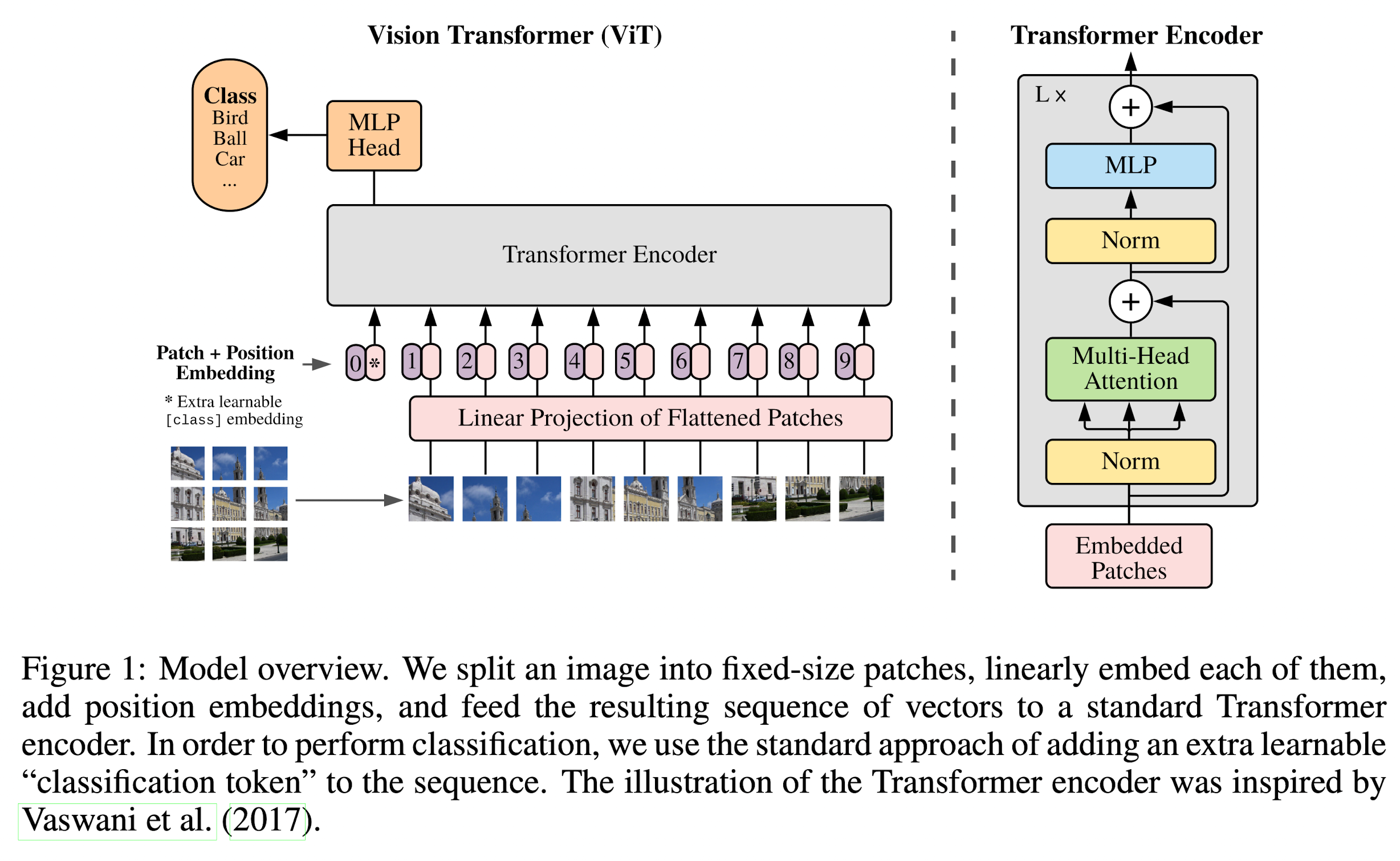
Vision Transformer (ViT)
The standard Transformer receives as input a 1D sequence of token embeddings. To handle 2D images, they reshape the image \(x \in \mathbb{R}^{H \times W \times C}\) into a sequence of flattened 2D patches \(N \times \textbf{x}_p \in \mathbb{R}^{P^2 \cdot C}\), where \((H, W)\) is the resolution of the original image, \(C\) is the number of channels, \((P, P)\) is the resolution of each image patch, and \(N = HW / P^2\) is the resulting number of patches, which also serves as the effective input sequence length for the Transformer.
Note
The Transformer uses constant latent vector size \(D\) through all of its layers, so they flatten the patches and map to \(D\) dimensions with a trainable linear projection.
Classification Head
Similar to BERT's [class] token, they prepend a learnable embedding to the sequence of embedded patches (\(\textbf{z}^0_0 = \textbf{x}_{class}\)), whose state at the output of the Transformer encoder (\(\textbf{z}_L^0\)) serves as the image representation \(\textbf{y}\). Both during pre-training and fine-tuning, a classification head is attached to \(\textbf{z}_L^0\).
Note
The classification head is implemented by a MLP with one hidden layer at pre-training time and by a single linear layer at fine-tuning time.
Position Embedding
Position embeddings are added to the patch embeddings to retain positional information. They use standard learnable 1D position embeddings.
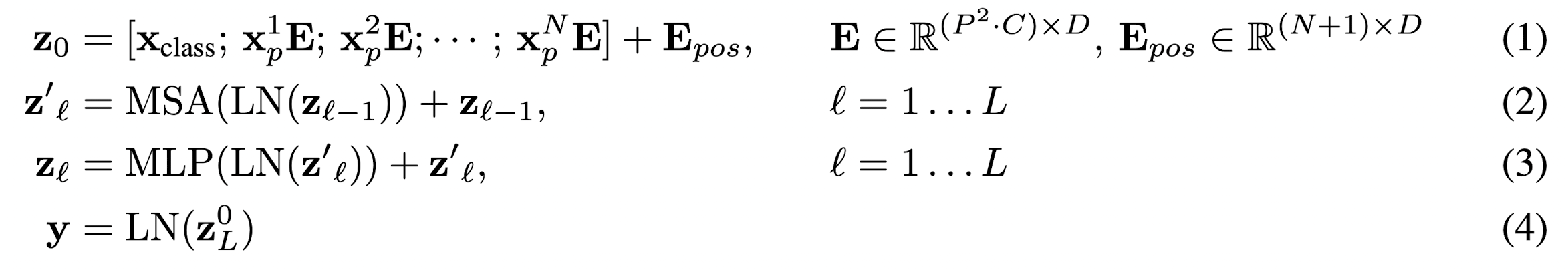
Inductive Bias
Vision Transformer has much less image-specific inductive bias than CNNs.
- In CNNs, locality, two-dimensional neighborhood structure, and translation equivariance are baked into each layer throughout the whole model.
- In ViT, only MLP layers are local and translationally equivariant, while the self-attention layers are global.
Hybrid Architecture
As an alternative to raw image patches, the input sequence can be formed from feature maps of a CNN. In this hybrid model, the patch embedding projection \(\textbf{E}\) is applied to patches extracted from a CNN feature map.