YOLOv4: Optimal Speed and Accuracy of Object Detection

Abstract
There are a huge number of features which are said to improve Convolutional Neural Network (CNN) accuracy. Practical testing of combinations of such features on large datasets, and theoretical justification of the result, is required.
- Some features operate on certain models exclusively and for certain problems exclusively, or only for small-scale datasets;
- while some features, such as batch-normalization and residual-connections, are applicable to the majority of models, tasks, and datasets.
Introduction
The main goal of this work is designing a fast operating speed of an object detector in production systems and optimization for parallel computations, rather than the low computation volume theoretical indicator (BFLOP).
Related Work
Object Detection Models
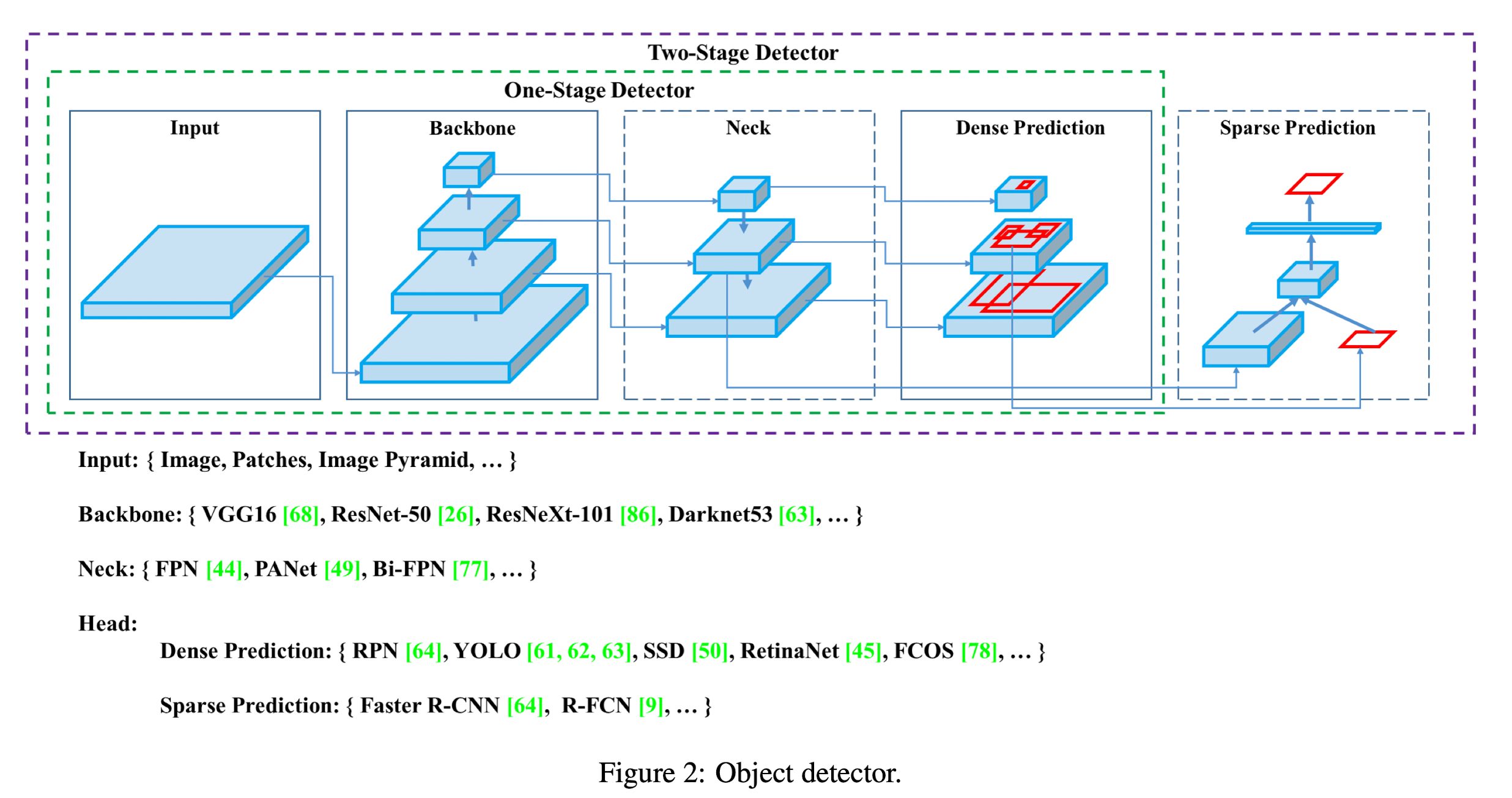
A modern detector is usually composed of two parts, a backbone which is pre-trained on ImageNet and a head which is used to predict classes and bounding boxes of objects. Object detectors developed in recent years often insert some layers between backbone and head, and these layers are usually used to collect feature maps from different stages. They call it the neck of an object detector.
Bag of Freebies
They call methods that only change the training strategy or only increase the training cost as "bag of freebies".
Data Augmentation
Bag of Specials
For those plugin modules and post-processing methods that only increase the inference cost by a small amount but can significantly improve the accuracy of object detection, they call them "bag of specials".
Methodology
Note
The basic aim is fast operating speed of neural network, in production systems and optimization for parallel computations, rather than the low computation volume theoretical indicator (BFLOP).
They present two options of real-time neural networks:
- For GPU, they use a small number of groups (1 - 8) in convolutional layers: CSPResNeXt50/CSPDarknet53.
- For VPU, they use grouped-convolution, but they retrain from using Squeeze-and-excitement (SE) blocks -- specifically this includes the following models: EfficientNet-lite/MixNet/GhostNet/MobileNetV3.
Selection of Architecture
- The objective is to find the optimal balance among the input network resolution, the convolutional layer number, the parameter number (filter_size^2 * filters * channel/groups), and the number of layer outputs (filters).
- The next objective is to select additional blocks for increasing the receptive field and the best method of parameter aggregation from different backbone levels for different detector levels: e.g. FPN, PAN, ASFF, BiFPN
Hint
A reference model which is optimal for classification is not always optimal for a detector.
In contrast to the classifier, the detector requires the following:
- Higher input network size (resolution) - for detecting multiple small-sized objects.
- More layers - for a higher receptive field to cover the increased size of input network.
- More parameters - for greater capacity of a model to detect multiple objects of different sizes in a single image.
The influence of the receptive field with different sizes is summarized as follows:
- Up to the object size - allows viewing the entire object.
- Up to network size - allows viewing the context around the object.
- Exceeding the network size - increases the number of connections between the image point and the final activation.
They add the SPP block over the CSPDarknet53, since it significantly increases the receptive field, separates out the most significant context features and causes almost no reduction of the network operation speed. They use PANet as the method of parameter aggregation from different backbone levels for different detector levels, instead of the FPN used in YOLOv3.
Note
They choose CSPDarknet53 backbone, SPP additional module, PANet path-aggregation neck, and YOLOv3 (anchor based) head as the architecture of YOLOv4.
Selection of BoF and BoS
For improving the object detection training, a CNN usually uses the following:
- Activations: ReLU, leaky-ReLU, parametric-ReLU, ReLU6, SELU, Swish, or Mish
- Bounding box regression loss: MSE, IoU, GIoU, CIoU, DIoU
- Data augmentation: CutOut, MixUo, CutMix
- Regularization method: DropOut, DropPath, Spatial DropOut, or DropBlock.
- Normalization of the network activations by their mean and variance: Batch Normalization (BN), Cross-GPU Batch Normalization (CGBN or SyncBN), Filter Response Normalization (FRN), or Cross-Iteration Batch Normalization (CBN).
- Skip-connections: Residual connections, Weighted residual connections, Multi-input weighted residual connections, or Cross stage partial connections (CSP)
Additional Improvements
In order to make the designed detector more suitable for training on single GPU, they made additional design and improvement as follows:
- They introduce a new method of data augmentation Mosaic, and Self-Adversarial Training (SAT).
- They select optimal hyper-parameters while applying genetic algorithms.
- They modify some existing methods to make the design suitable for efficient training and detection.