YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors

Abstract
YOLOv7 surpasses all known object detectors in both speed and accuracy.
Introduction
The computing devices that execute real-time object detection is usually some mobile CPU or GPU, as well as various neural processing units (NPU) developed by major manufacturers. The proposed real-time object detector mainly support mobile GPU and GPU devices from the edge to the cloud.
The development direction of the proposed methods in this paper are different from that of the current mainstream real-time object detectors. Their focus is on some optimized modules and optimization methods which may strengthen the training cost for improving the accuracy of object detection, but without increasing the inference cost.
Hint
They call the proposed modules and optimization methods trainable bag-of-freebies.
Recently, model re-parameterization and dynamic label assignment have become important topics in network training and object detection. Mainly after the above new concepts are proposed, the training of object detector evolves many new issues. In this paper, they present some of the new issues and devise effective methods to address them.
Related Work
Real-time Object Detectors
Currently state-of-the-art real-time object detectors are mainly based on YOLO and FCOS. Being able to become a state-of-the-art real-time object detector usually requires the following characteristics:
- A faster and stronger network architecture
- A more effective feature integration method
- A more accurate detection method
- A more robust loss function
- A more effective label assignment method
- A more efficient training method
Model Re-parameterization
Note
Model re-parametrization techniques merge multiple computational modules into one at inference stage.
The model re-parameterization technique can be regarded as an ensemble technique, and we can divide it into two categories, i.e., module-level ensemble and model-level ensemble.
There are two common practices for model-level re-parameterization to obtain the final inference model.
- Train multiple identical models with different training data, and then average the weights of multiple trained models.
- Perform a weighted average of the weights of models at different iteration number.
Module-level re-parameterization is a more popular research issue recently. This type of method splits a module into multiple identical or different module branches during training and integrates multiple branched modules into a completely equivalent module during inference.
Warning
Not all proposed re-parameterized module can be perfectly applied to different architectures.
Model Scaling
Note
Model scaling is a way to scale up or down an already designed model and make it fit in different computing devices.
The model scaling method usually uses different scaling factors, such as resolution (size of input image), depth (number of layer), width (number of chanel), and stage (number of feature pyramid), so as to achieve a good trade-off for the amount of network parameters, computation, inference speed, and accuracy.
Architecture
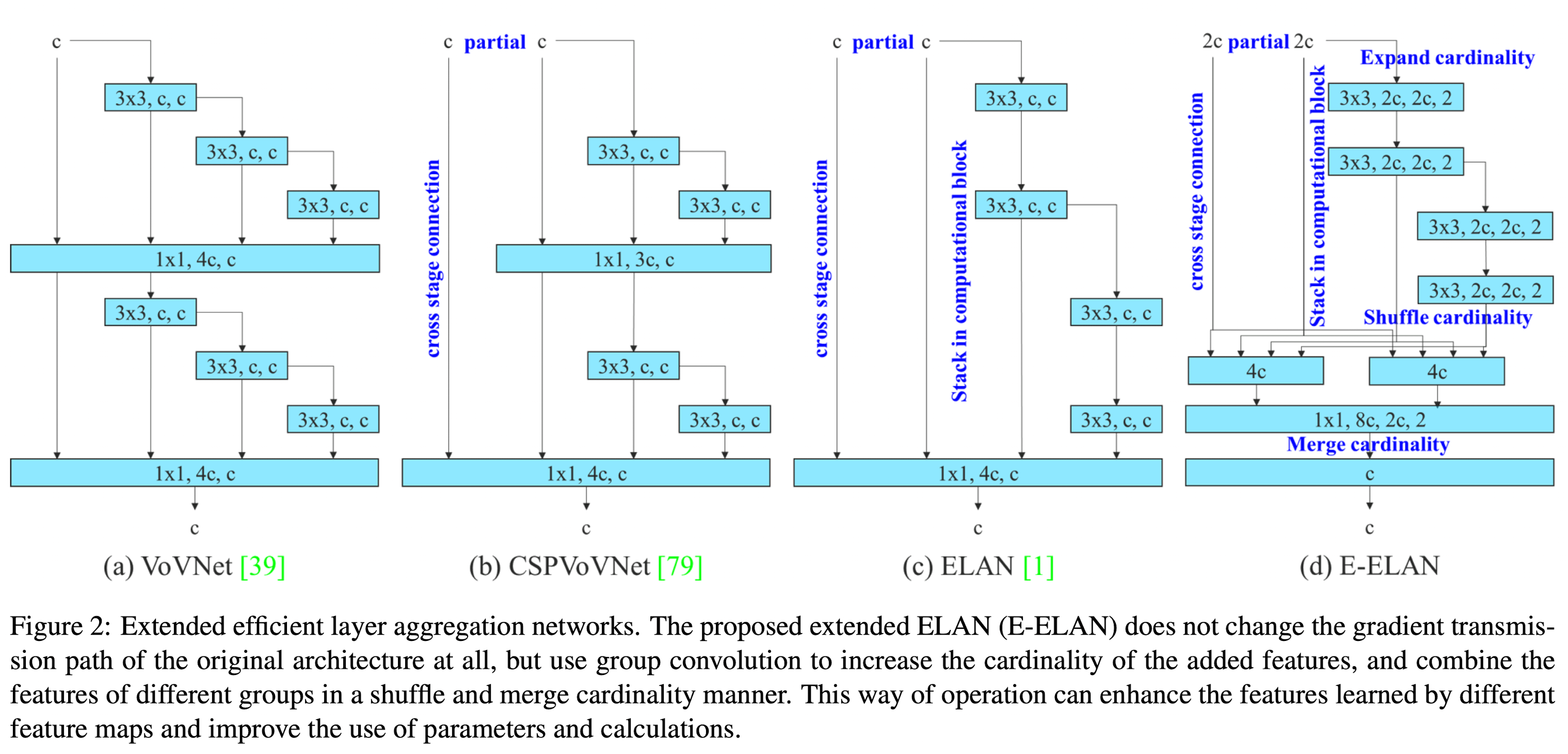
Extended Efficient Layer Aggregation Networks
In most of the literature on designing the efficient architectures, the main considerations are no more than the number of parameters, the amount of computation, and the computational density.
Memory Access Cost
- Input/Output channel ration
- Number of branches of the architecture
- Element-wise operation
Activation
Fast and Accurate Model Scaling
- Number of elements in the output tensors of the convolution layers.
VoVNet
An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
CSPVovNet
Scaled-YOLOv4: Scaling Cross Stage Partial Network
In addition to considering the aforementioned basic designing concerns, the architecture of CSPVoVNet also analyzes the gradient path, in order to enable the weights of different layers to learn more diverse features. The gradient analysis approach described above makes inferences faster and more accurate.
ELAN
Designing Network Design Strategies Through Gradient Path Analysis
Note
By controlling the longest gradient path, a deep network can learn and converge efficiently.
Regardless of the gradient path length and the stacking number of computational blocks in large-scale ELAN, it has reached a stable state. If more computational blocks are stacked un-limitedly, this stable state may be destroyed, and the parameter utilization rate will decrease. The proposed E-ELAN uses expand, shuffle, merge cardinality to achieve the ability to continuously enhance the learning ability of the network without destroying the original gradient path.
Model Scaling for Concatenation-based Models
The main purpose of model scaling is to adjust some attributes of the model and generate models of different scales to meet the needs of different inference speeds.
Trainable Bag-of-freebies
Planned Re-parameterized Convolution
Although RepConv has achieved excellent performance on the VGG, when we directly apply it to ResNet and DenseNet and other architectures, its accuracy will be significantly reduced.
- They use gradient flow propagation paths to analyze how re-parameterized convolution should be combined with different network.
- They also designed planned re-parameterized convolution accordingly.
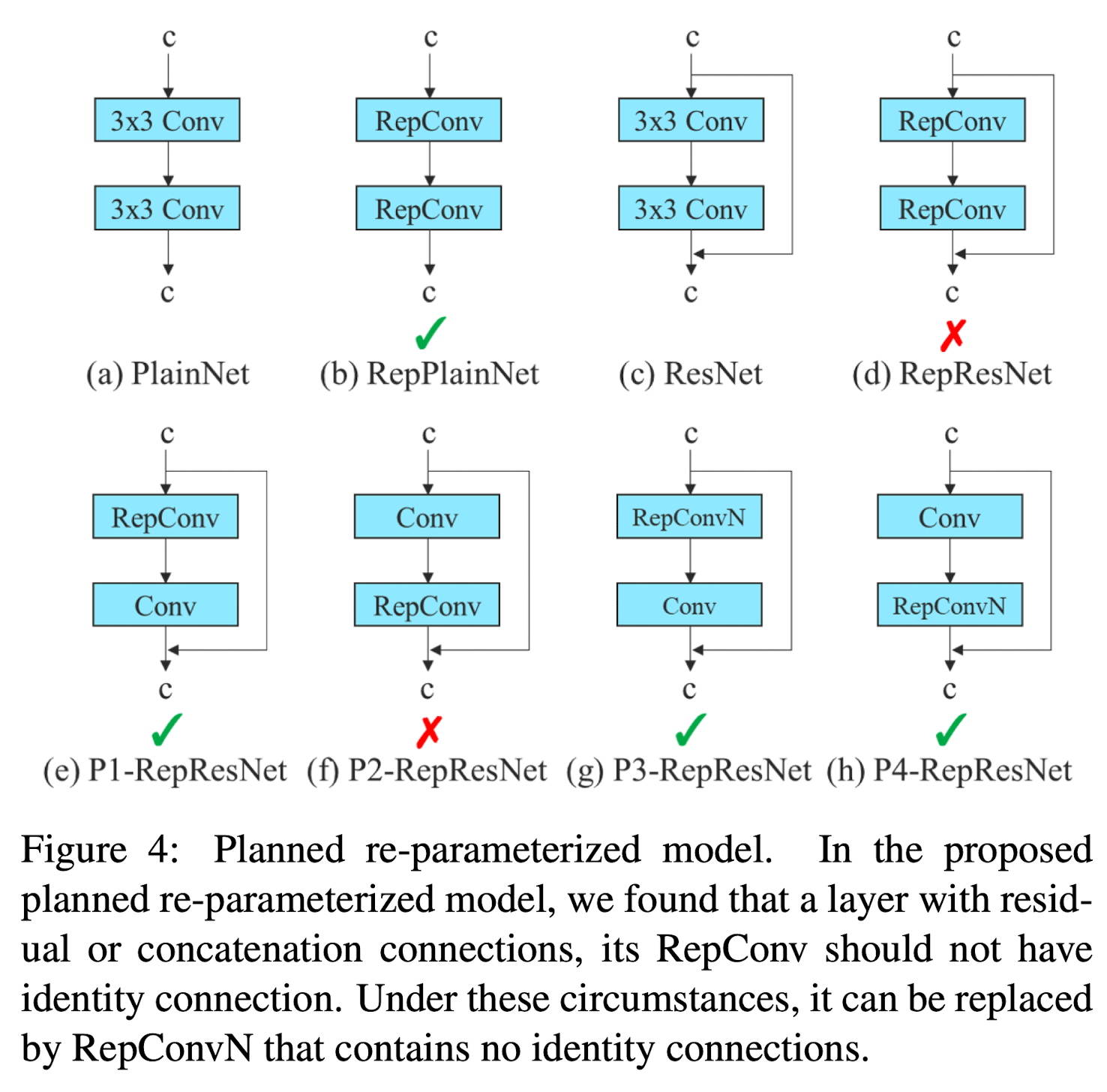
They found that the identity connection in RepConv destroys the residual in ResNet and the concatenation in DenseNet, which provides more diversity of gradients for different feature maps.
Coarse for Auxiliary and Fine For Lead Loss
Note
Deep supervision is a technique that is often used in training deep networks.
Its main concept is to add extra auxiliary head in the middle layers of the network, and the shallow network weights with assistant loss as the guide.
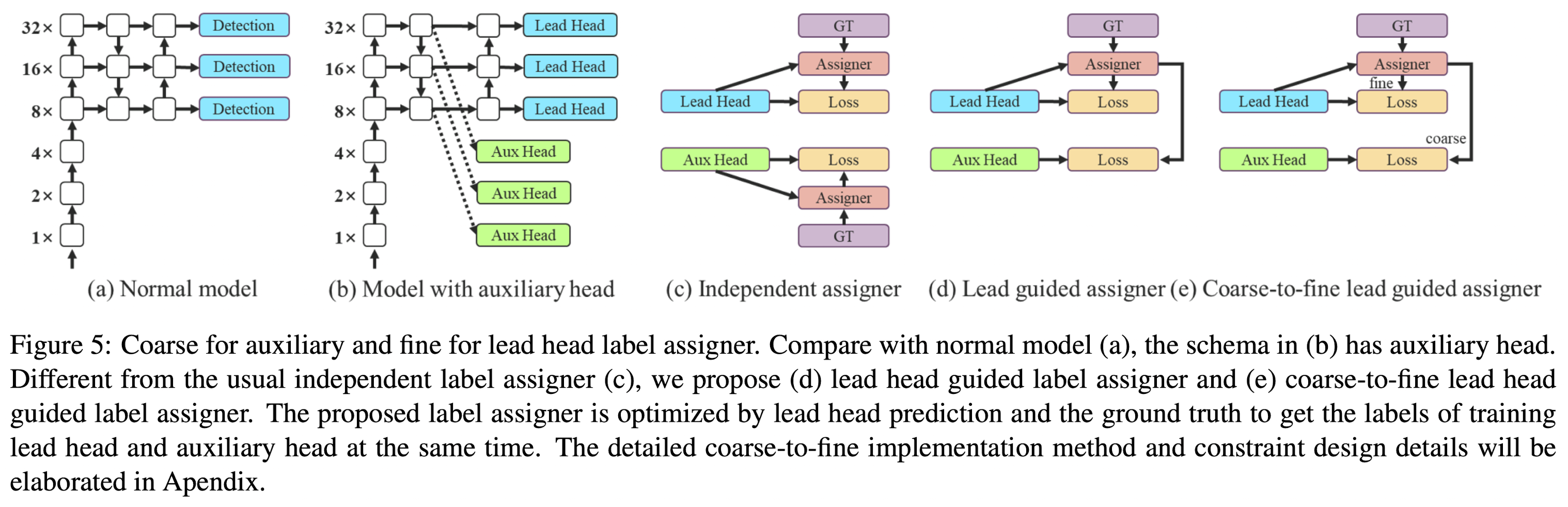
Label Assignment
- In the past, in the training of deep network, label assignment usually refers directly to the ground truth and generate hard label according to the given rules.
- In recent years, if we take object detection as an example, researchers often use the quality and distribution of prediction output by the network, and then consider together with the ground truth to use some calculation and optimization methods to generate a reliable soft label.
Lead Head Guided Label Assigner
Lead head guided label assigner is mainly calculated based on the prediction result of the lead head and the ground truth, and generate soft label through the optimization process.
Note
The reason to do this is because lead head has a relatively strong learning capability, so the soft label generated from it should be more representative of the distribution and correlation between the source data and the target.
By letting the shallower auxiliary head directly learn the information that lead head has learned, lead head will be more able to focus on learning residual information that has not yet been learned.